sandbox
Experimental projects and creative ideas. Each project is isolated in its own section for focused development and testing.
| Project | Description | Link |
|---|---|---|
| Song of the Day | Daily music discovery platform — one curated song per day | View Project |
| Pragotron Master Clock | Arduino-driven master clock for a vintage Czech slave clock | View Project |
| D365 ER Governance Tool | Audit and cleanup of Electronic Reporting configurations in D365 F&O | View Project |
| D365 Environment Manager | Unified Power Platform + LCS environment browser with drift detection and remediation | View Project |
| NBHeartBeat | Real-time brand intelligence and sentiment analysis platform | View Project |
| Cloud Trim | Custom Azure cost optimization UI — aggregates thousands of resources with actionable savings data | View Project |
Song of the Day
Song of the Day is a daily music discovery platform that surfaces one curated song per day. Live at songspot.fm, visitors get album artwork, a short editorial description, and a 30-second preview via the iTunes Search API. Registered users unlock the full archive; those with Apple Music subscriptions can connect their accounts for full-track playback directly in the browser.
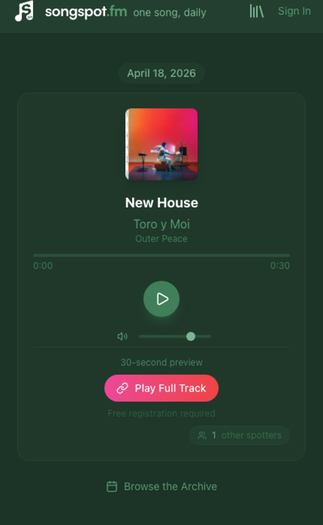
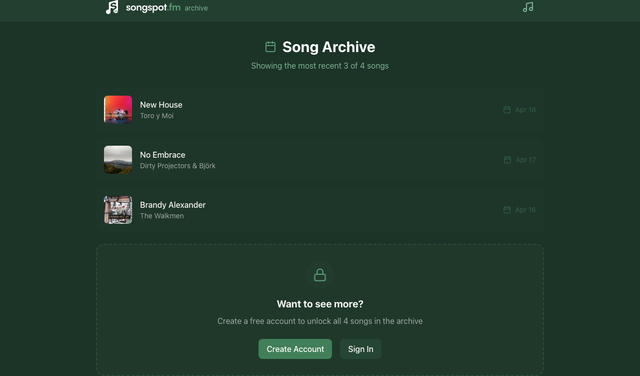
How it was built
Song of the Day was built almost entirely through conversation with Claude Code (Anthropic’s CLI agent, powered by Claude Sonnet 4). From initial scaffolding through production deployment, every component — database schema, API routes, authentication, MusicKit integration, admin tooling — was authored, debugged, and iterated on within Claude Code sessions. The project serves as a real-world proof-of-concept for AI-assisted application development at production quality.
That said, Claude Code is a tool, not a substitute for engineering judgement. The human in the loop drove every meaningful decision: choosing SQLite over a managed database for deployment simplicity, separating admin and user auth domains to limit blast radius, splitting the power stage from logic in the MusicKit provider to avoid state leaks, and pushing back when the AI suggested over-engineered abstractions where straightforward code would do. UX choices — the 30-second preview as the default experience, the progressive disclosure from anonymous visitor to registered user to Apple Music subscriber — came from understanding how people actually discover music, not from a prompt. AI-assisted development at this level requires a solid technical foundation to direct the conversation, evaluate trade-offs, and recognise when the tool is confidently wrong.
Architecture
The application is a server-rendered Next.js 14 App Router project
with a clear separation between server and client components. Pages
follow a consistent pattern: a server-side page.tsx handles
auth checks and data fetching, then renders a page-client.tsx
client component for interactivity.
The system is organised into five layers:
- Data layer — SQLite via better-sqlite3 with
WAL mode for concurrent reads. Three tables:
admin_users,users(with lockout tracking and Apple Music connection state), andtracks(scheduled songs with Apple Music metadata). The database auto-initializes its schema on first import. - API layer — RESTful endpoints organised by
domain:
/api/auth(user login/register/logout),/api/admin(track CRUD and scheduling),/api/tracks(public today/archive),/api/apple-music/search(iTunes proxy), and/api/musickit/token(JWT generation for MusicKit playback). - Authentication — two separate session domains (admin and user), both using iron-session encrypted cookies with 7-day expiry. Account lockout triggers after 5 failed attempts with a 15-minute cooldown. Passwords hashed with bcrypt at cost 12.
- Music integration — iTunes Search API
provides free 30-second previews and metadata. Apple MusicKit JS
SDK v3 enables full-track streaming for subscribers, with
server-side JWT token generation using the
joselibrary. - Admin tooling — a protected admin panel for searching the iTunes catalog, writing editorial descriptions, scheduling tracks to specific dates, and monitoring listener activity.
Stack
| Framework | Next.js 14 (App Router) / React 19 |
| Language | TypeScript |
| Database | SQLite (better-sqlite3, WAL mode) |
| Styling | Tailwind CSS — dark emerald theme |
| Auth | iron-session (encrypted cookies) + bcryptjs |
| Music | iTunes Search API + Apple MusicKit JS SDK v3 |
| Hosting | Railway (nixpacks builder) |
| Storage | Railway persistent volume (SQLite at /data) |
| AI tooling | Claude Code (Claude Sonnet 4) |
Deployment
The site deploys directly from GitHub to Railway via automatic
deploys. Every push to main on the
scottheydorn/songspot-fm repository triggers a nixpacks
build, runs npm run build, and deploys the production
Next.js server. Railway provides a persistent volume mounted at
/data where the SQLite database lives, surviving
redeploys without data loss. The custom domain
songspot.fm is configured at the Railway service level
with automatic TLS.
Security
Production security controls include comprehensive HTTP headers (Content-Security-Policy, HSTS, X-Frame-Options), encrypted session cookies, account lockout with brute-force protection, bcrypt password hashing, and CSRF safeguards. The admin panel is fully isolated from the public-facing user authentication domain.
← Back to ProjectsPragotron Master Clock
The Pragotron Master Clock is a custom Arduino-based controller that drives a vintage Czechoslovak Pragotron slave clock movement. Built entirely from scratch — no third-party clock libraries — it generates the alternating ±24 V pulses required to advance the minute hand, displays the current time on a small TFT, and keeps itself running indefinitely via a hardware watchdog.

Background
Pragotron slave clocks, manufactured in Czechoslovakia from the 1950s through the 1990s, were installed in thousands of schools, factories, and train stations across the Eastern Bloc. The units have no internal timekeeping — each one expects a central "master clock" to send a 24 volt pulse once per minute, alternating polarity on every pulse. A positive pulse advances the hand one minute; the next pulse must be negative to advance it again. Without the polarity swap the mechanism simply will not step. The goal of this project was to replace the long-gone original master clock with a small, reliable, modern controller that is accurate to the second and self-recovers from any fault.
Architecture
The controller is split between two physical units: a wooden enclosure housing the Arduino, the TFT display, and the user controls, and an externally mounted perfboard carrying the power-stage electronics. Keeping the 24 V switching hardware away from the low-voltage logic reduces EMI coupling into the microcontroller.
Functionally the system is organised into four layers:
- Timekeeping — a DS3231 real-time clock module provides drift-free minute-accurate time, backed up by a CR2032 cell so the clock survives power cycles without losing sync.
- Scheduler — the main loop polls the RTC and
fires a pulse event at the rollover of each minute. Scheduling is
derived from a single
minuteOfEpochcounter so pulse polarity can always be recomputed deterministically (odd/even = ±). - Output stage — an L298N dual H-bridge motor
driver module switches a regulated 24 V rail across the
Pragotron coil. Two Arduino GPIO pins (
PIN_A,PIN_B) select direction; both-low is the idle state. Upstream of the H-bridge, a DC-DC buck converter provides clean, adjustable voltage for the coil drive. - Supervisor — the AVR built-in watchdog timer is armed with an 8-second timeout and kicked on every successful loop iteration. If the program stalls, the chip resets itself and picks up from the RTC, never losing real-world time.

Pulse generation
The heart of the project is a short routine that emits a single polarity-correct pulse. The H-bridge is driven in one direction for the coil energisation window, then returned to an idle state so the coil is not left powered:
const uint16_t PULSE_MS = 250; // Coil energisation time
void emitPulse(bool positive) {
if (positive) {
digitalWrite(PIN_A, HIGH);
digitalWrite(PIN_B, LOW);
} else {
digitalWrite(PIN_A, LOW);
digitalWrite(PIN_B, HIGH);
}
delay(PULSE_MS);
digitalWrite(PIN_A, LOW);
digitalWrite(PIN_B, LOW); // return H-bridge to idle
}Pulse polarity is derived from the absolute minute counter, not a toggling boolean — this way a watchdog reset or power glitch can never leave the controller and the slave clock out of phase:
void tickMinute(uint32_t minuteOfEpoch) {
bool positive = (minuteOfEpoch & 1) == 0;
emitPulse(positive);
}Keeping it running: the watchdog
Early bench testing revealed the Arduino would occasionally freeze, most likely from EMI generated by the 24 V switching coupling back into the logic rail. The fix was two-fold: improved decoupling near the MCU (and physical separation of the power stage onto its own perfboard), plus the AVR watchdog timer configured to force a reboot if the main loop ever stops making progress:
#include <avr/wdt.h>
void setup() {
// ... hardware init: RTC, H-bridge pins, TFT ...
wdt_enable(WDTO_8S); // 8-second hardware timeout
}
void loop() {
if (minuteRollover()) {
tickMinute(currentMinute());
}
updateDisplay();
wdt_reset(); // "I am still alive"
}If loop() ever stops executing — stack overflow,
I²C bus hang, glitched interrupt — wdt_reset()
stops being called, the watchdog fires, and the chip reboots. On reboot,
the RTC is re-read and the next pulse polarity is derived from the
absolute minute counter, so the slave clock stays in sync with zero
manual intervention.
Enclosure and display
The master clock lives in a small hand-built wooden enclosure labelled with the Pragotron logo. A TFT panel on top shows, at a glance: UTC and local time to the second, the polarity and duration of the last pulse sent, and a rolling UTC seconds counter. Two front-panel controls — an illuminated indicator button and a momentary push button — handle manual advance and reset, which is useful after a long power outage when the slave clock hands need to be re-aligned with real time.

D365 ER Governance Tool
The D365 ER Governance Tool is an audit and cleanup utility for Electronic Reporting (ER) configurations in Microsoft Dynamics 365 Finance & Operations. Developed for a large retail client operating across multiple regions, it addresses a persistent governance challenge: D365 environments accumulate hundreds of ER configurations over time — many country-specific, deprecated, or entirely unused — with no built-in tooling to identify which can be safely removed.
The problem
Electronic Reporting is the D365 framework for generating regulatory documents: tax filings, payment formats, invoices, Intrastat declarations, and similar country-specific output. Microsoft ships hundreds of ER configurations through the Global Repository, and environments that have been live for any length of time tend to accumulate a sprawling catalogue of formats, data models, and model mappings. Many target countries the organisation does not operate in. Others are older versions superseded by newer releases. Some have never been executed at all.
The cost is not just clutter. Excess ER configurations slow down the Globalization Studio sync process, inflate Dataverse storage, and create confusion for functional consultants trying to identify which formats are actually in use. D365 provides no native view that cross-references configurations against execution history, parameter bindings, or legal entity geography — so cleanup has historically been a manual, error-prone process that most teams simply avoid.
Architecture
The tool is a Python application with a Streamlit web interface that queries two separate API surfaces and correlates their data to classify every ER configuration in the environment:
- Dataverse (Globalization Studio) —
the tool downloads gzipped ER index files from the
msdyn_electronicreportingconfigurationsindexfilestable and parses them into a flat catalogue of all configurations, including name, version, status, provider, country target, and GUID. It also discovers and scans additional Dataverse tables (format destinations, solution metadata) for active usage signals. - D365 F&O OData — the tool queries the Finance environment’s OData endpoints to collect execution history (which formats have actually run), parameter table references (which formats are pinned in GL parameters, tax setup, payment modes, print management, etc.), and legal entity country codes to determine which country-specific configurations are relevant.
Authentication supports three methods: Azure CLI tokens (for developer use), interactive browser sign-in via MSAL, and service principal credentials for automated/pipeline scenarios.
Classification engine
The analyser classifies every configuration into one of four categories:
- Required (green) — recently executed, referenced in a parameter or setup table, has a custom (non-Microsoft) provider, or is a dependency of another required configuration.
- Country Mismatch (orange) — targets a country code that does not appear in any of the environment’s legal entities. The tool normalises both ISO 3166 alpha-2 and alpha-3 codes so that e.g. “DE” and “DEU” are treated as equivalent.
- Deprecated Version (yellow) — an older version of a configuration where a newer version with the same GUID exists, or marked as Obsolete in the repository. A warning is surfaced that version-specific pinning in parameter forms must be verified before deletion.
- Unused (red) — no execution history, no parameter references, no dependency relationships, and no country match. Safest candidates for removal.
Dependency analysis walks the parent–child tree so that a data model is never flagged for removal if any of its child model mappings or formats are classified as required.
Interface
The Streamlit UI is organised into four tabs:
- Dashboard — summary metrics (total, required, removable, custom) and interactive Plotly charts showing classification breakdown and top-20 countries by configuration count.
- Audit Report — filterable, searchable table of all configurations with classification, reason, last execution date, and provider. Exportable to CSV for offline review with functional consultants.
- Cleanup Actions — checkbox-based selection with quick-select buttons for all country mismatches or all deprecated versions. Deletion is ordered (formats first, then mappings, then data models) to respect dependency constraints, with a confirmation gate before execution.
- Dependencies — interactive tree visualisation of the ER configuration hierarchy, colour-coded by classification, so reviewers can trace why a particular configuration is or is not flagged for removal.
Stack
| Language | Python |
| UI | Streamlit |
| Charting | Plotly Express |
| Auth | MSAL (Azure CLI, interactive, SPN) |
| Data sources | Dataverse Web API + D365 F&O OData |
| Data processing | pandas + NumPy |
| AI tooling | Claude Code (Claude Sonnet 4) |
D365 Environment Manager
The D365 Environment Manager is a lightweight desktop tool that consolidates environment data from Microsoft’s Power Platform Admin API and Lifecycle Services (LCS) into a single-page interface. Developed for a large retail client managing dozens of D365 Finance & Operations environments across NA, EMEA, and APAC regions, it provides an at-a-glance snapshot of commonly referenced environment variables — build versions, platform updates, ER solution versions, deployment history, freeze status, and ownership — that are otherwise scattered across multiple portals and API surfaces.
The problem
Managing a portfolio of D365 F&O environments means constantly cross-referencing data from at least three separate sources: the Power Platform Admin Center for environment metadata and state, LCS for build versions and deployment history, and Dataverse for Globalization Studio configuration versions. None of these surfaces present a unified view. Determining whether an environment is running the expected application build, whether its ER solution is current, or who owns a particular sandbox requires navigating multiple portals, waiting for slow page loads, and mentally correlating data across tabs.
This fragmentation creates a deeper operational risk: configuration drift. When environments are maintained independently — different teams deploying packages at different cadences, sandbox refreshes overwriting metadata, ad-hoc changes to ER configurations — it becomes difficult to know whether any given environment is in its expected state. Undetected drift leads to failed deployments, broken integrations, and wasted troubleshooting time when the root cause is simply that an environment is running a different build or configuration than assumed.
Architecture
The tool is a Python/FastAPI application with a vanilla JavaScript single-page frontend. It authenticates via Azure CLI tokens and queries three API surfaces in a progressive enrichment pattern:
- Phase 1: Power Platform BAP API (instant) — fetches all Microsoft-hosted D365 F&O environments with display name, SKU (Production/Sandbox/ Trial), state, region, and Dataverse/Finance URLs. Environment metadata — purpose, tier, region, owner, freeze status — is stored as structured key-value pairs in the environment description field and parsed on retrieval.
- Phase 2: Dataverse Web API (~10 seconds) — parallel async queries to each environment’s Dataverse instance to retrieve the installed Globalization (ER) Solution version. Failures are handled gracefully; environments with unreachable Dataverse endpoints still appear in the list.
- Phase 3: LCS API (minutes) — paginated queries with rate-limit handling (6 calls/min) to retrieve application build version, platform version, release names, and the last deployment date and package. Results are cached server-side for 30 minutes to avoid repeated slow pagination on refresh.
This three-phase approach means the UI is usable within seconds of launch — basic environment data appears immediately, with build and version details progressively filling in as the slower API calls complete.
Drift detection and remediation
Beyond inventory, the tool is designed as the foundation for active environment governance. By aggregating environment state into a single data model, it enables drift detection: comparing the current state of each environment against an expected baseline and surfacing discrepancies. Planned capabilities include:
- Configuration drift alerts — flagging environments where the application build, platform version, or ER solution version deviates from the expected value for its tier and region.
- API write-back — using the Power Platform BAP PATCH endpoint to update environment metadata (owner, purpose, freeze status) directly from the tool, with full audit logging of every change.
- Triggered remediation — invoking build and deployment pipelines via Azure DevOps API when unplanned drift is detected, ensuring environments are brought back to a known state without manual intervention.
- Scheduled monitoring — periodic automated scans that compare environment snapshots over time, generating drift reports and alerting environment owners when their environments fall out of compliance.
The objective is a closed-loop system: detect drift, notify the right people, and where safe to do so, trigger the appropriate corrective action automatically — keeping the full portfolio of D365 environments in a known, validated state.
Interface
The UI is a dark-themed single-page application built with vanilla JavaScript. Environments are displayed in a sortable table with columns for name, SKU, state, purpose, tier, region, owner, ER solution version, application build, platform version, and freeze status. Clicking a row expands an inline editing panel with visual diff highlighting — changed fields are marked with yellow borders before save. Concurrent multi-environment updates, toast notifications, and a full audit trail panel round out the interface.
Additional features include field inference (automatically suggesting purpose, tier, and region from environment naming conventions), JSON export for offline analysis, and one-click Confluence publishing to generate a timestamped environment inventory page for stakeholder review.
Stack
| Backend | Python / FastAPI + Uvicorn |
| Frontend | Vanilla JavaScript (single HTML file) |
| Auth | Azure CLI token acquisition (MSAL fallback) |
| Data sources | Power Platform BAP API + LCS API + Dataverse Web API |
| Storage | SQLite (audit log, config cache) |
| Publishing | Confluence Cloud REST API |
| AI tooling | Claude Code (Claude Opus 4) |
NBHeartBeat
NBHeartBeat is a real-time brand intelligence and sentiment analysis platform built for a major athletic footwear company. It continuously monitors mentions across social media, news outlets, sneaker culture publications, video channels, and review platforms — aggregating content from over a dozen sources into a single dashboard with live sentiment scoring, engagement-weighted trends, and quality complaint detection.
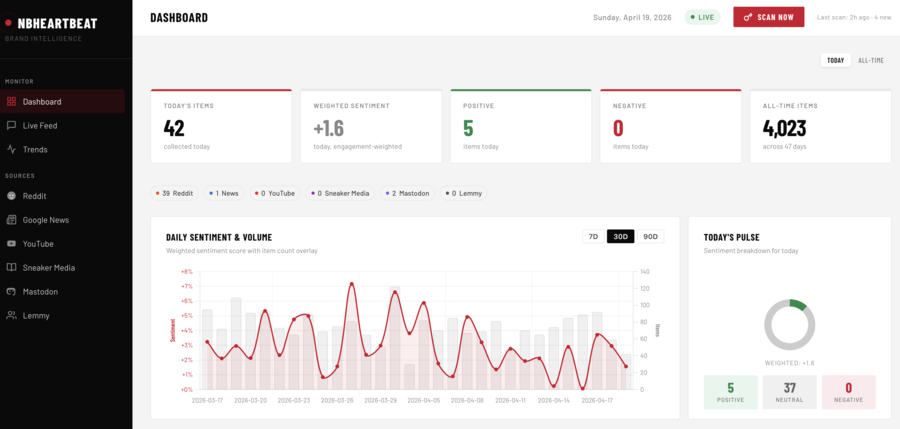
The problem
Brand perception in the sneaker industry moves fast. A single viral post about a quality defect, a surprise collaboration announcement, or a trending colourway can shift sentiment overnight. Traditional brand monitoring tools are expensive, slow to configure, and poorly calibrated for sneaker culture — where words like “crazy,” “sick,” “insane,” and “fire” are enthusiastic praise, not negative commentary. Off-the-shelf sentiment libraries (AFINN, VADER) consistently misclassify this language, producing misleading trend data that erodes confidence in the analysis.
The objective was to build a lightweight, self-hosted platform that could be tuned precisely for the brand’s domain — sneaker culture, running communities, streetwear media — and provide an honest, calibrated signal rather than a noisy one.
Architecture
The application is a Node.js/Express server with a SQLite database and a single-page dashboard frontend. Scans run on a cron schedule (three times daily) or on demand, with each scan cycling through all configured sources, filtering for brand relevance, scoring sentiment, and storing results for trend analysis.
The system is organised into four layers:
- Data collection — a multi-source scanner queries public APIs and RSS feeds across Reddit (general search plus targeted subreddits), Google News, sneaker media outlets (SneakerNews, Hypebeast, Nice Kicks, Highsnobiety), YouTube creator channels, Mastodon and Lemmy federated instances, and optionally Bluesky, Trustpilot, and Discord. Each source has its own rate limiting, pagination strategy, and error isolation so a single source failure never blocks the rest of the scan.
- Relevancy filtering — items are matched against explicit brand mentions and model number patterns (990, 574, 550, 2002R, 9060, etc.), with context-aware exclusions for gaming communities, replica marketplaces, and deal aggregator spam. A blocklist of 50+ subreddit and keyword patterns prevents false positives from unrelated contexts that happen to share terminology.
- Sentiment analysis — a custom engine built on top of the AFINN-165 word list with domain-specific lexicon overrides, a quality complaint detector, and engagement-weighted aggregation (described below).
- Dashboard — a responsive single-page interface with Chart.js visualisations showing sentiment trends over time, per-source item counts, top positive and negative mentions, and live scan status with a manual trigger button.
Sentiment engine tuning
The heart of the platform is a sentiment scoring engine that can be tuned at three levels: lexicon overrides, pattern detectors, and source weighting.
Lexicon overrides
The base AFINN-165 dictionary assigns scores to ~3,700 common English words, but many of those scores are wrong for sneaker culture. The engine maintains a custom lexicon of ~60 terms that override the AFINN defaults:
- Hyperbole inversion — words like “crazy,” “insane,” “sick,” “nasty,” and “deadly” are scored as positive (+1 to +3) rather than their AFINN negatives (-1 to -3). In sneaker discussion, “these are insane” is a compliment.
- Product enthusiasm — terms like “grail,” “cop,” “fire,” “heat,” “banger,” and “slaps” are scored +3 to +4 as strong purchase or approval signals.
- Deal language — “steal” and “stealing” are scored +2 to +3 rather than their AFINN negatives, since “got it for a steal” is positive brand engagement.
- Violence neutralisation — words like “kill,” “dead,” and “murder” are set to zero, since they appear in both positive (“killing it”) and negative (“dead after two months”) contexts and are best handled by the pattern detector instead.
- Model number recognition — specific model codes (990, 574, 550, 2002R, 1906R, 327, 9060) receive a small positive boost (+1) as mentions of specific products generally indicate engaged discussion.
The lexicon is designed to be hot-swappable — new terms can be added or existing scores adjusted without modifying the core analysis logic, allowing the engine to be recalibrated as language evolves.
Quality complaint detection
Standard word-list sentiment analysis has a critical blind spot: negation. “Not comfortable” contains the positive word “comfortable” and scores positively unless the negation is explicitly detected. The engine includes a pattern-based quality complaint detector that catches four failure modes:
- Negation patterns — “not comfortable,” “no grip,” “never again” → -4 penalty per match.
- Descriptor-noun pairing — “disappointing quality,” “flimsy build” → -4 penalty.
- Degradation verbs — “quality declined,” “sole separated,” “stitching came apart” → -4 penalty.
- Unindexed standalone negatives — negative descriptors near quality-related nouns that AFINN does not index.
A penalty cap of -12 prevents runaway stacking in long complaint posts, ensuring that even a detailed quality rant produces a proportionate negative score rather than an extreme outlier.
Source weighting
Daily sentiment aggregates use engagement-weighted scoring rather than simple averaging. Each item’s contribution to the daily aggregate is weighted by its engagement signal:
weight = max(1, upvotes + (comments × 2))
This means a Reddit post with 500 upvotes and 80 comments influences the daily sentiment score far more than a news article with no measurable engagement. The minimum weight of 1 ensures every item contributes, but high-engagement content — which better represents actual community sentiment — dominates the signal. Sources without native engagement metrics (RSS feeds, news articles) default to a weight of 1, while social platforms with upvote and comment counts naturally receive higher weighting. This approach allows the engine to be tuned by adjusting the engagement multiplier, adding per-source weight coefficients, or introducing source-level credibility scores — without changing the underlying sentiment scoring logic.
Title text is analysed with double weight (duplicated in the combined analysis text), reflecting the outsized influence of headlines and post titles on both engagement and reader perception.
Stack
| Runtime | Node.js 18+ (with built-in SQLite) |
| Server | Express.js |
| Database | SQLite 3 (WAL mode) |
| Sentiment | AFINN-165 + custom sneaker-culture lexicon (~60 overrides) |
| Scheduling | node-cron (3× daily + on-demand) |
| Sources | Reddit, Google News, Sneaker Media RSS, YouTube, Mastodon, Lemmy, Bluesky, Trustpilot, Discord |
| Dashboard | Chart.js + vanilla JavaScript |
| AI tooling | Claude Code (Claude Opus 4) |
Cloud Trim
Cloud Trim is a custom web application that aggregates cost data, resource inventory, utilization metrics, and optimization recommendations for thousands of Azure resources across an organization’s subscriptions into a single operational dashboard. Built for a large retail company managing cloud infrastructure across multiple regions, it pulls data from Microsoft’s native Azure APIs, runs it through a Cloud Custodian policy engine to identify waste and enforce tagging governance, and surfaces actionable savings data that translates raw cloud telemetry into clear business decisions.
The problem
Azure provides powerful cost management and optimization tools — Cost Management, Advisor, Resource Graph, Monitor — but they exist as separate portals, each with its own query language, export format, and access model. For an enterprise running dozens of subscriptions with thousands of resources, answering basic questions (“What are we spending by cost center?” “Which VMs are idle?” “Are all resources tagged correctly?”) requires navigating multiple surfaces and manually correlating data that was never designed to be viewed together.
The deeper challenge is accountability. Without normalized tagging and automated cost allocation, there is no reliable way to charge infrastructure costs back to the business units that incur them. Untagged resources become invisible spend. Idle VMs and orphaned disks accumulate because no one has a consolidated view of what is running, what it costs, and whether it is still needed. Azure Advisor identifies savings opportunities, but its recommendations are scattered across subscriptions and lack the resource-level detail needed to act on them confidently.
Enterprise value
The application is designed to deliver measurable business outcomes, not just technical visibility:
- Cost allocation and chargeback — every dollar of Azure spend is attributed to a cost center, project, environment, owner, or application through normalized tagging. This enables accurate monthly chargeback reports that finance teams can use directly, eliminating the manual spreadsheet reconciliation that typically consumes days each billing cycle.
- Waste elimination — policy-driven detection of idle VMs, unattached disks, orphaned public IPs, oversized instances, and expired snapshots surfaces concrete savings opportunities with dollar amounts attached. Each finding links to the specific resources involved, their current monthly cost, and the estimated savings from remediation.
- Reservation and savings plan guidance — Azure Advisor recommendations are ingested, grouped by category, and enriched with affected resource lists so that procurement teams can evaluate reserved instance and compute savings plan purchases with full context: which resources benefit, what the commitment costs, and what the projected annual savings are.
- Tagging governance — tag compliance is measured per subscription and surfaced as a percentage score. Resources missing required tags are identified for remediation, and the application provides bulk tagging operations to close coverage gaps at scale rather than one resource at a time.
- Executive reporting — pre-built reports (executive summary, subscription overview, cost center chargeback, tag compliance, waste summary) give leadership a clear picture of cloud spend health without requiring Azure portal access or technical expertise.
Architecture
The application is built on Python/FastAPI with a server-rendered UI, a PostgreSQL data store, and a CLI for both interactive use and scheduled pipeline execution. Data flows through four ingestion pipelines that run independently and can be triggered on demand or via scheduled jobs:
- Cost ingestion — pulls daily cost records from the Azure Cost Management REST API, broken down by resource, meter category, and billing period. Supports three ingestion modes (API, blob storage exports, local files) for flexibility across environments. Idempotent upserts ensure re-runs never duplicate data.
- Resource inventory — queries
Azure Resource Graph across all subscriptions to
snapshot every resource with its type, location,
SKU, provisioning state, and tags. A tag normalizer
applies regex-based rules to standardize inconsistent
tag keys across teams and regions (e.g.
“Cost Center,” “cost-center,”
“COSTCENTER” all resolve to
cost_center). - Utilization metrics — collects CPU, memory, disk I/O, and network metrics from Azure Monitor for VMs, App Service plans, SQL databases, and AKS clusters. These time-series data points feed the Cloud Custodian policy engine to distinguish genuinely idle resources from those with intermittent workloads.
- Advisor recommendations — ingests cost optimization recommendations from Azure Advisor, deduplicates by lookback period, and extracts savings estimates, SKU details, and commitment terms for reservation and savings plan analysis.
All four pipelines write to a shared PostgreSQL database with a materialized view that joins costs to normalized tags, enabling instant cost allocation queries across five dimensions without expensive runtime joins.
Policy engine
The application extends Cloud Custodian — the open-source cloud governance framework — with a custom plugin that adds cost-aware and utilization-aware filters not available in the base project. This is the key differentiator: standard Cloud Custodian can find idle VMs, but it cannot distinguish a $5/month idle dev box from a $2,000/month idle production instance. The custom filters cross-reference live Azure Monitor metrics and actual Cost Management spend data against each resource, enabling policies like “flag VMs with average CPU below 5% over 14 days that cost more than $500/month” — targeting high-value waste rather than generating noise.
Nineteen starter policies ship with the application, covering idle and oversized VMs, unattached disks, orphaned network resources, unused storage accounts, empty App Service plans, expired snapshots, and security findings (open firewalls, public storage access, expiring Key Vault keys). Each policy runs in read-only mode — no automatic modifications — and records findings with severity, affected resource, current cost, and estimated savings percentage. Findings are surfaced in the UI for human review before any action is taken.
Interface
The UI is a server-rendered web application using HTMX for lightweight interactivity without a JavaScript build step. Pages are organized around the cost optimization workflow:
- Dashboard — 30-day spend summary with month-over-month comparison, top cost centers, total potential savings from pending findings, tag coverage percentage, and resource inventory count.
- Cost allocation — interactive cost grouping by any of five tag-based dimensions (cost center, project, environment, owner, application), with an unallocated spend view that highlights resources missing required tags.
- Policies — browse findings with filtering and sorting, discover and run available policies, create custom policies via a YAML generator, and apply bulk tagging operations to untagged resources.
- Advisor action plan — Azure Advisor recommendations grouped by category and ranked by savings impact, with expandable implementation steps and affected resource lists for each recommendation group.
- Reports — executive summary, subscription overview, cost center chargeback, tag compliance, and waste summary — each designed to be shared directly with stakeholders.
- D365 environment analysis — specialized views for Dynamics 365 F&O infrastructure, grouping resources by detected environment with cost attribution and resource type breakdowns.
Stack
| Backend | Python / FastAPI + Uvicorn (fully async) |
| Frontend | Jinja2 server-rendered templates + HTMX |
| Database | PostgreSQL 16 (SQLAlchemy 2.0 async + Alembic) |
| Policy engine | Cloud Custodian + custom plugin (cost-aware filters) |
| Azure APIs | Cost Management, Resource Graph, Monitor, Advisor |
| Data processing | pandas + PyArrow (Parquet/CSV) |
| Auth | Azure Identity (Service Principal + Azure CLI) |
| Notifications | Microsoft Graph API (email) + Teams webhooks |
| Infrastructure | Azure Container Apps + PostgreSQL Flexible Server (Bicep IaC) |
| AI tooling | Claude Code (Claude Opus 4) |